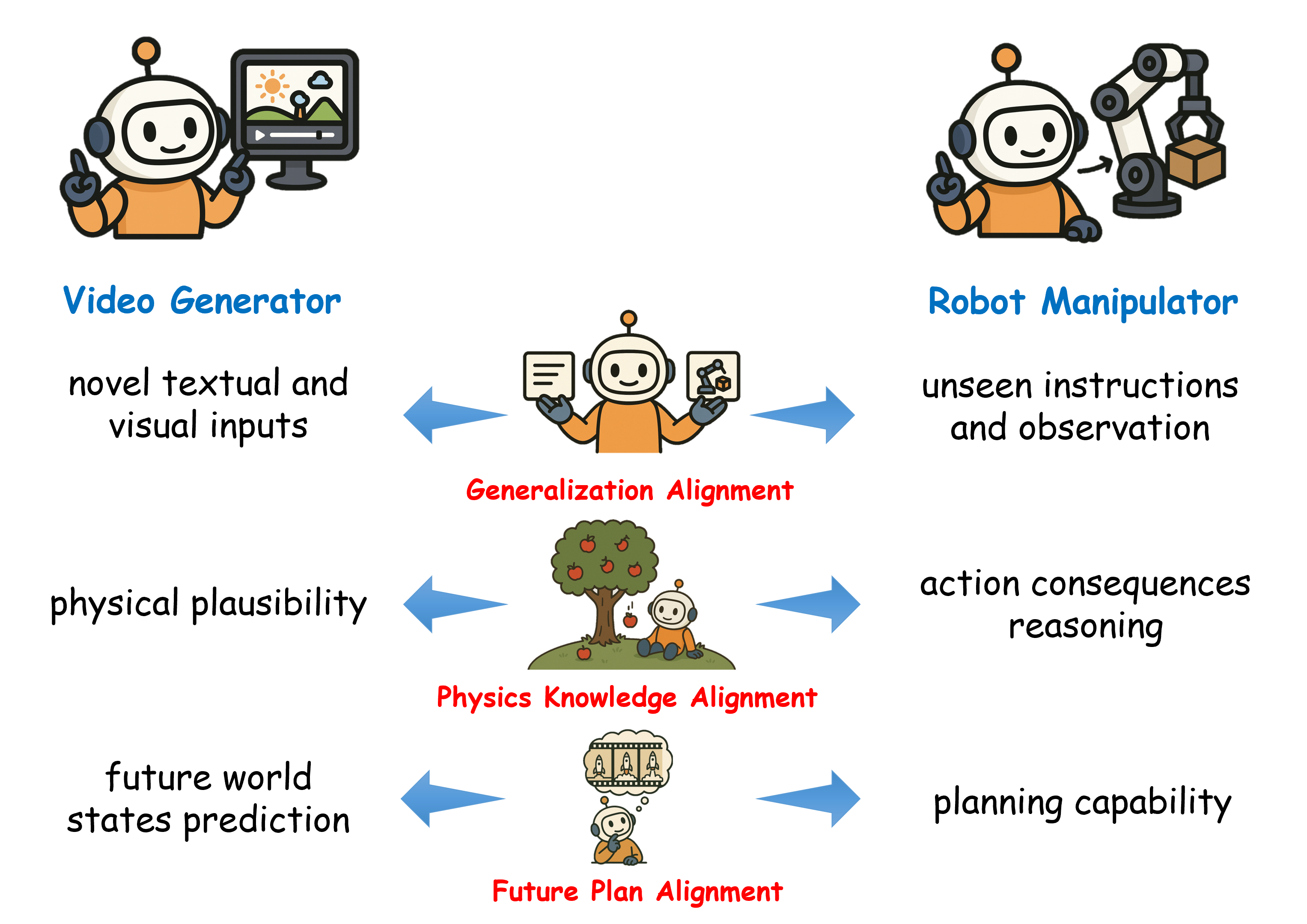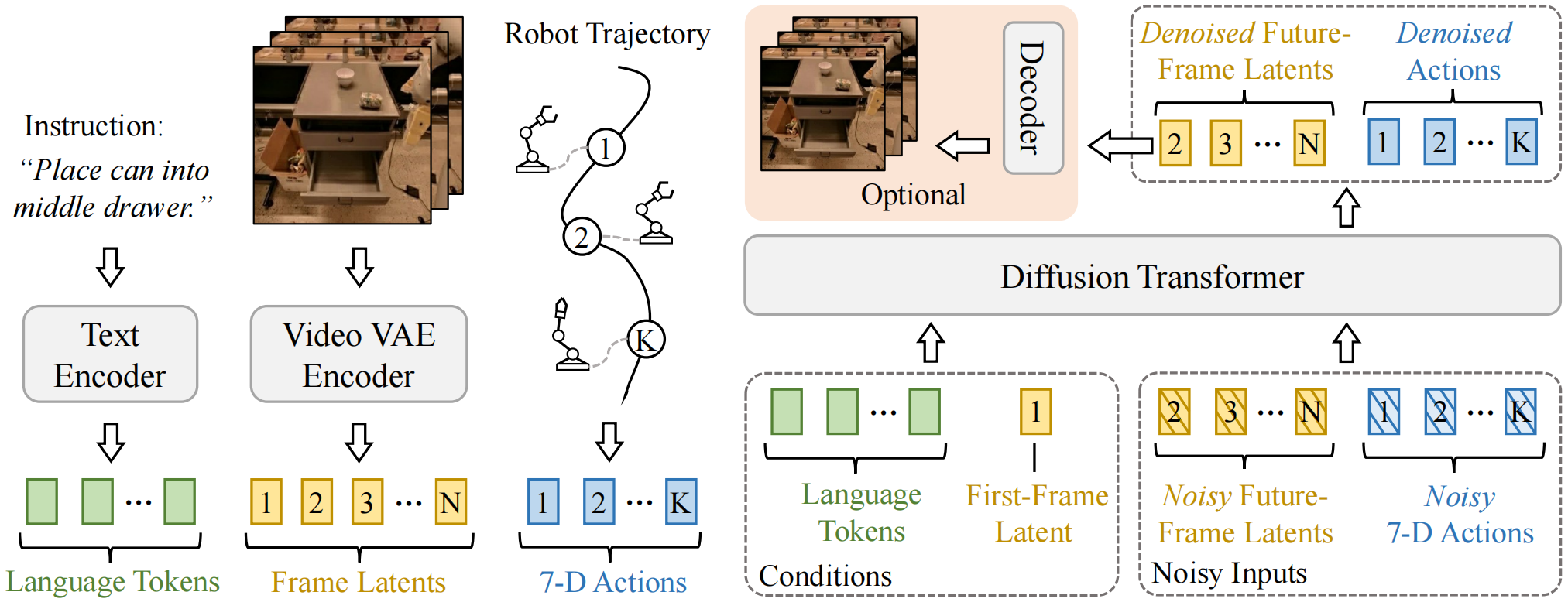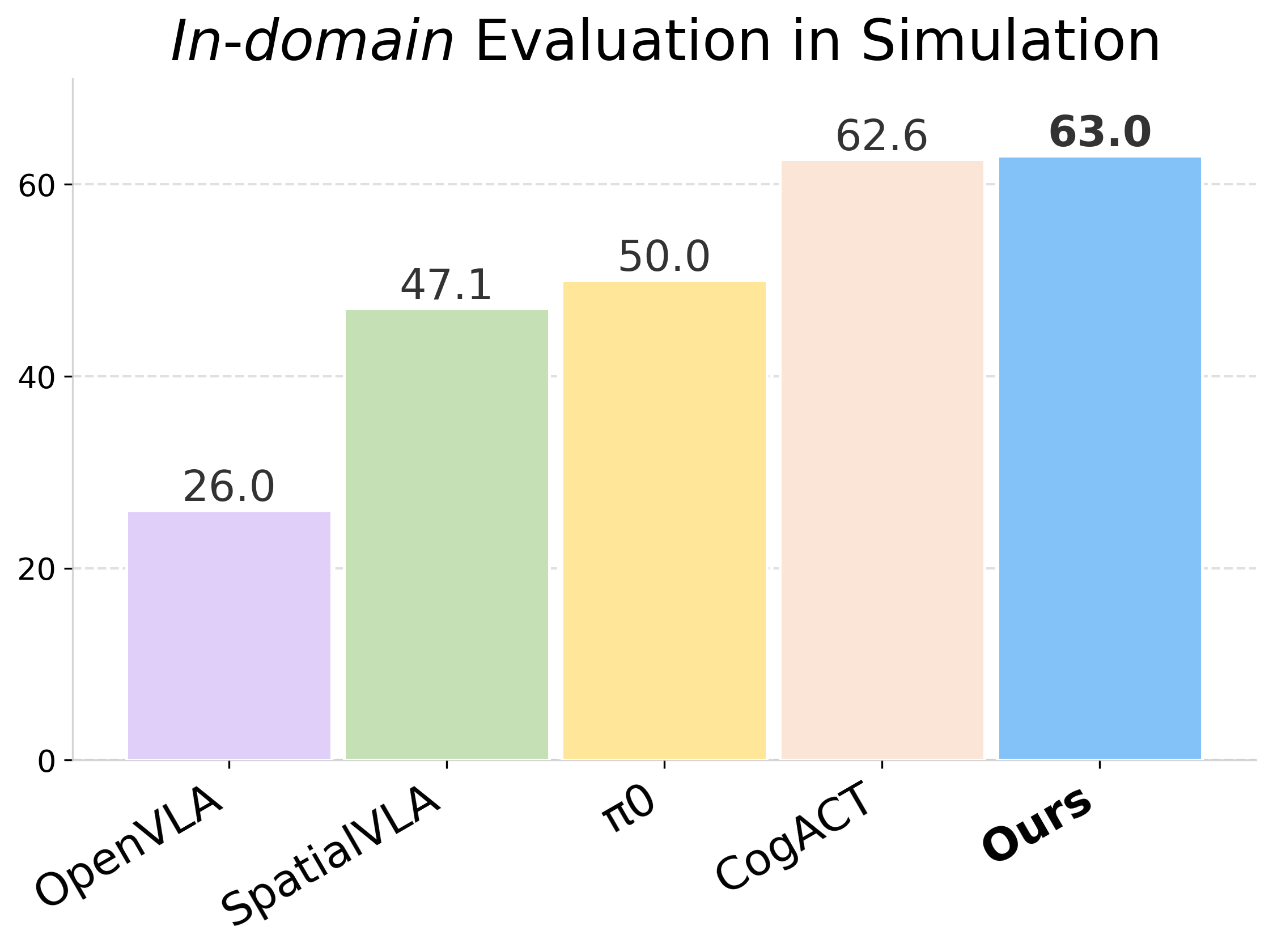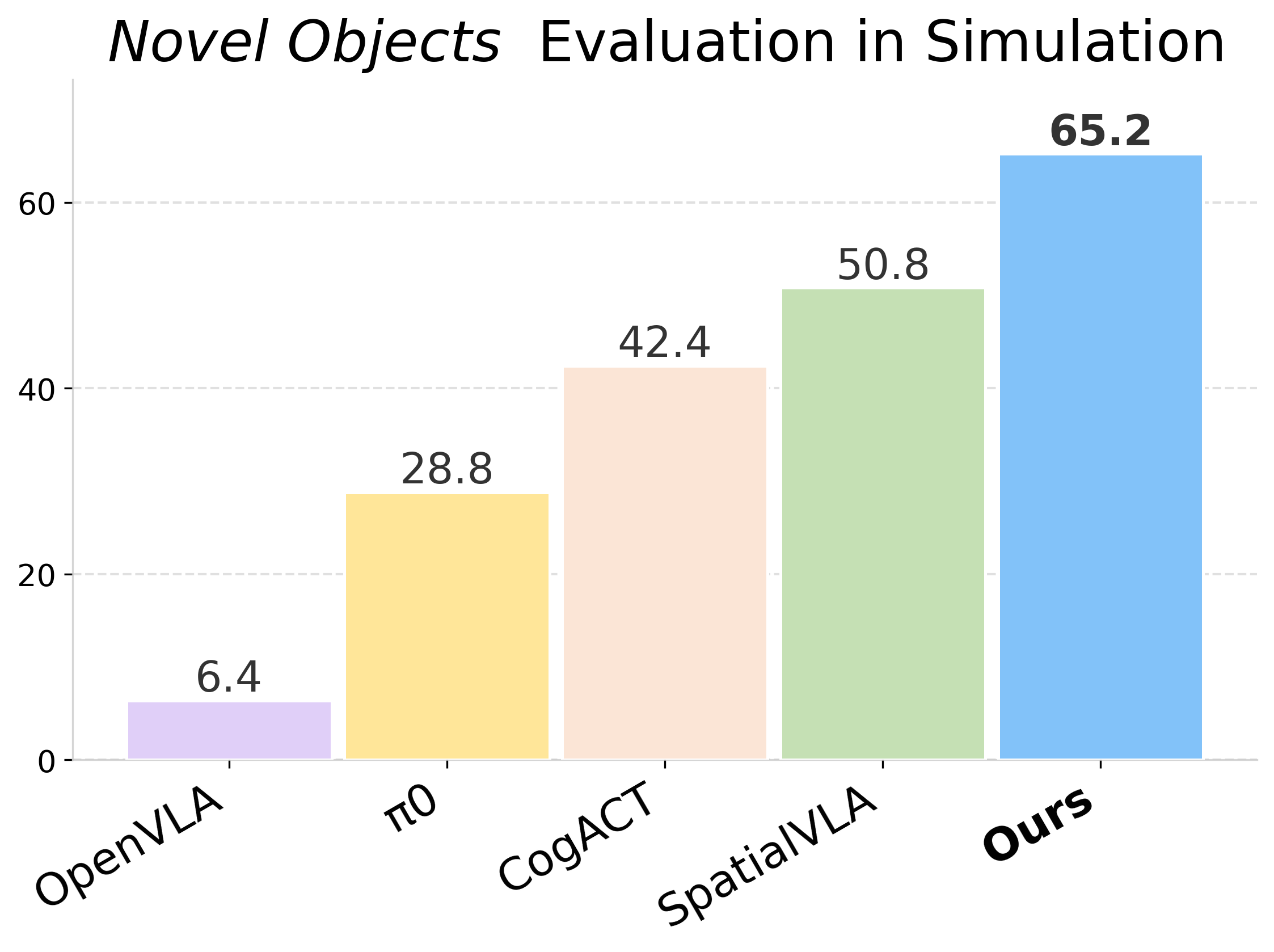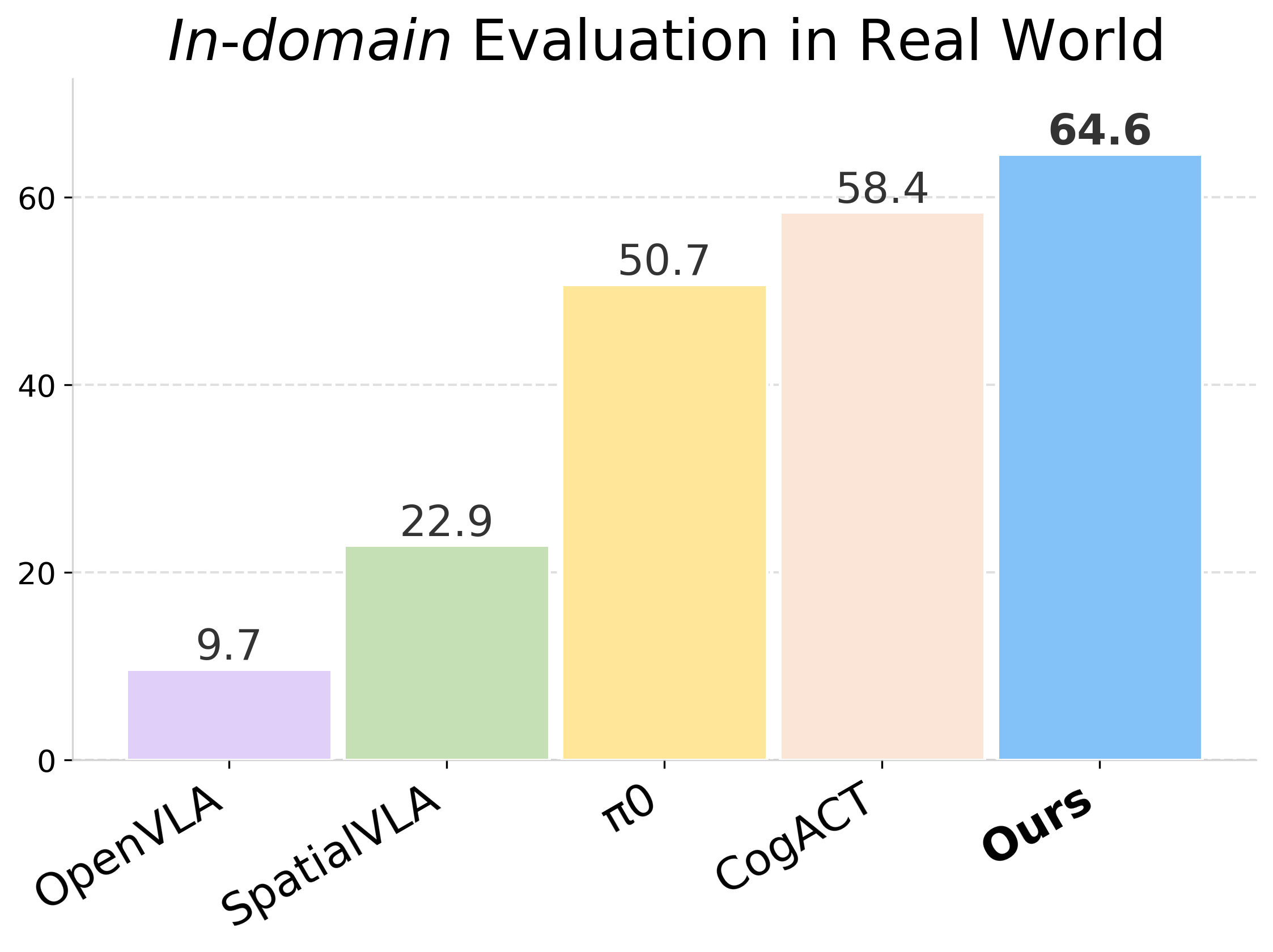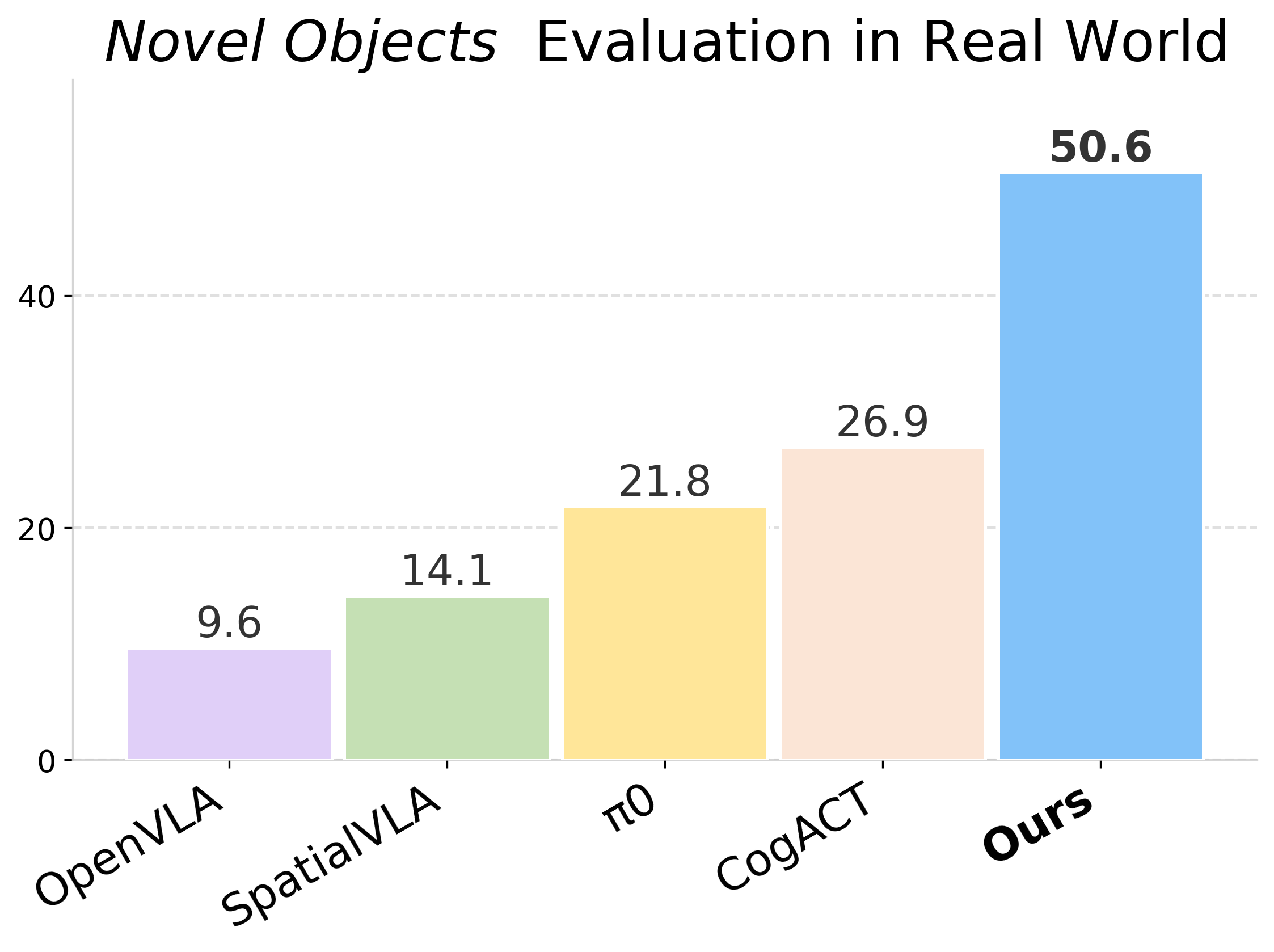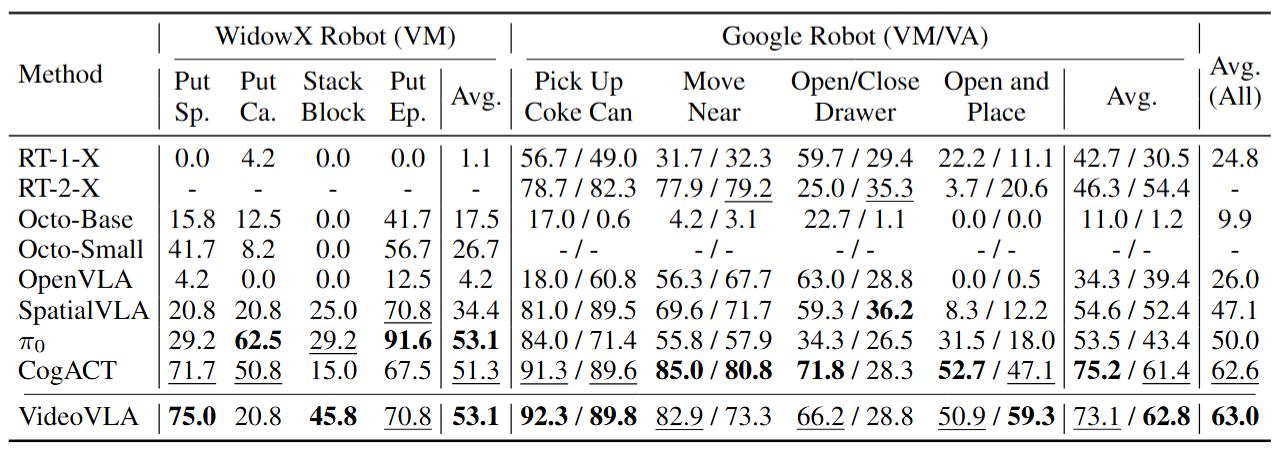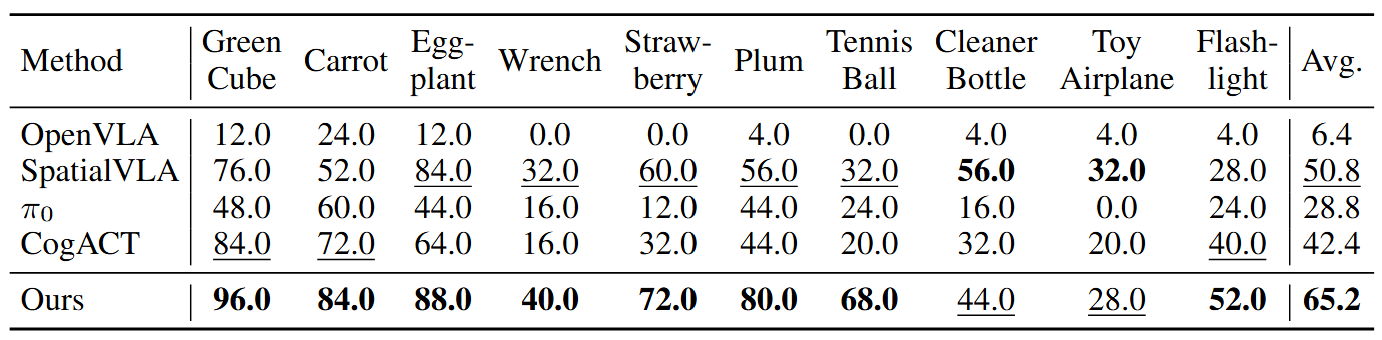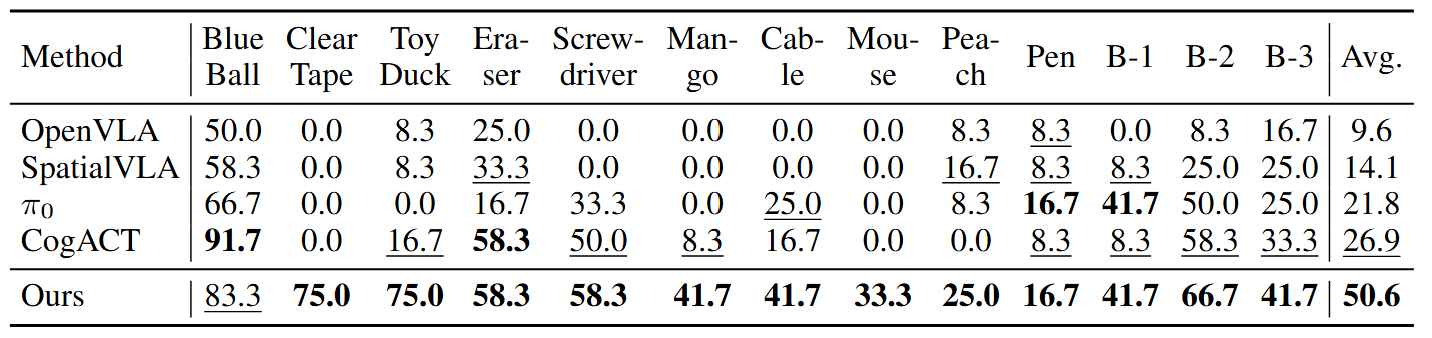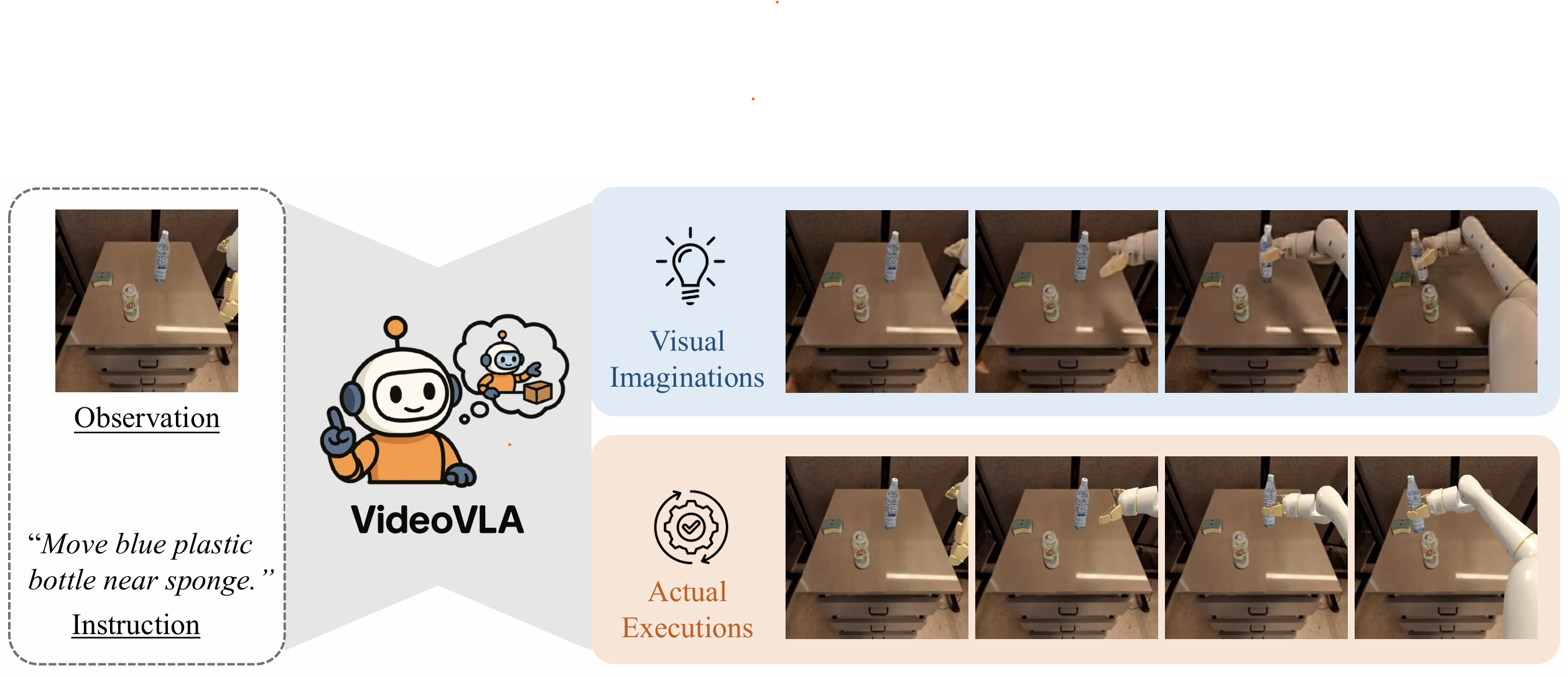
We present VideoVLA, a simple approach that explores the potential of directly transforming large video generation models into robotic VLA manipulators. Given a language instruction and an image, VideoVLA predicts an action sequence as well as the future visual outcomes. Built on a multi-modal Diffusion Transformer, VideoVLA jointly models video, language, and action modalities, using pre-trained video generative models for joint visual and action forecasting. Our experiments show that high-quality imagined futures correlate with reliable action predictions and task success, highlighting the importance of visual imagination in manipulation. VideoVLA demonstrates strong generalization, including imitating other embodiments’ skills and handling novel objects. This dual-prediction strategy—forecasting both actions and their visual consequences—explores a paradigm shift in robot learning and unlocks generalization capabilities in manipulation systems.